Edited to move to the bundle with shared dashboard ready to go.
As we setup our important infrastructure we set up monitoring and alerting so that we can keep a close eye on infrastructure. As the services we provide grow and need to expand, or failures in hardware attempt to wreck havoc, we’re ready because of the due diligence that’s gone into monitoring the infrastructure and applications deployed. One thing I often see is that folks forget to monitor the tools that coordinates all of their deployment and configuration management. It’s a bit of a case of “who watches the watcher?”.
While building and operating JAAS (Juju as a Service) we’ve had to make sure that we follow the same best practices for our Juju hosting infrastructure that you’d use on your production systems you run in JAAS. This means that our Juju Controllers (the state and event tracking back end) need to be watched to make sure that we’re ready to prevent any issues we can see coming and know about issues as soon as possible for the ones we cannot.
Fortunately, there’s some great established tools for doing this. We use Prometheus, Grafana, and Telegraf to help us keep our JAAS infrastructure running smoothly. What’s better, is that there are Charms available for each that enable us to quickly and easily deploy, configure, and operate the monitoring setup. This means you can replicate the operational knowledge we’ve gained by reusing the same exact Charms we use in production.
Getting our Controller set up
Let’s walk through an example set up. First, we’ll create a new controller on GCE where we’re going to run our production applications. Note that this will work for any Controller on any cloud you choose to run Juju on.
$ juju bootstrap google production
...
Bootstrap complete, "production" controller now available.
Controller machines are in the "controller" model.
Initial model "default" added.
One interesting thing in the output at the end is that your “Controller machines” are in the controller model. We want to watch those so let’s switch to that model and work from there.
$ juju switch controller
production:admin/default -> production:admin/controller
The next thing we’re going to do is to make sure our controller is HA enabled so we have replication and resiliency to our controller.
$ juju enable-ha -n 3
While that goes forward let’s setup our monitoring user account we need so that we can ask Juju about the metrics it is capable of spitting out.
$ juju add-user prometheus
$ juju grant prometheus read controller
$ juju change-user-password prometheus
<enter a super secret password>
Next up we need to setup the bundle we’re going to use to tie together our monitoring infrastructure to our controller machines. For now, we have to cheat. Juju can only form relations between applications in the model and controllers aren’t an application in the model. We’re going to cheat by using a bundle that deploys a generic Ubuntu charm onto the controller machines and then use that to relate to our other infrastructure.
Let’s pull down the bundle we’re going to use to set things up.
$ charm pull cs:~juju-qa/controller-monitor
$ cd controller-monitor
$ ls
bundle.yaml dashboard.json overlay.yaml README.md
We’ve got to tweak the bundle for our specific controller setup. We’re going to need the IP addresses of the controllers and the password we used above for our prometheus user account. The IP addresses are available in the juju status output.
$ juju status
...
0 started 35.196.134.151 juju-e7e6c5-0 bionic us-east1-b RUNNING
1 started 34.73.102.169 juju-e7e6c5-1 bionic us-east1-b RUNNING
2 started 35.231.100.156 juju-e7e6c5-2 bionic us-east1-c RUNNING
… and edit the overlay.yaml we’ll use to tweak the install. Fill out the $IPADDRESS and the $PROMETHEUS_PASSWORD variables in the overlay.
prometheus:
options:
scrape-jobs: |
- job_name: juju
...
static_configs:
- targets:
- '$IPADDRESS0:17070'
...
- targets:
- '$IPADDRESS1:17070'
...
- targets:
- '$IPADDRESS2:17070'
...
basic_auth:
username: user-prometheus
password: $PROMETHEUS_PASSWORD
With that we should be able to deploy our bundle onto our model and get things off to the races.
$ juju deploy ./bundle.yaml --overlay=overlay.yaml --map-machines=existing
This will deploy the monitoring infrastructure onto our existing three Juju controller machines. You can watch the status go through and once it settles we can load up Grafana and add our dashboard.
$ watch --color juju status --color
Once everything is settled we can ask Grafana for what the admin password is and load up the webui by going to the address of the unit.
$ juju run-action grafana/0 --wait get-login-info
unit-grafana-0:
UnitId: grafana/0
id: "1"
results:
password: 4Jg3PXJWTTkSprVx
url: http://34.73.102.169:3000/
username: admin
$ xdg-open http://34.73.102.169:3000/
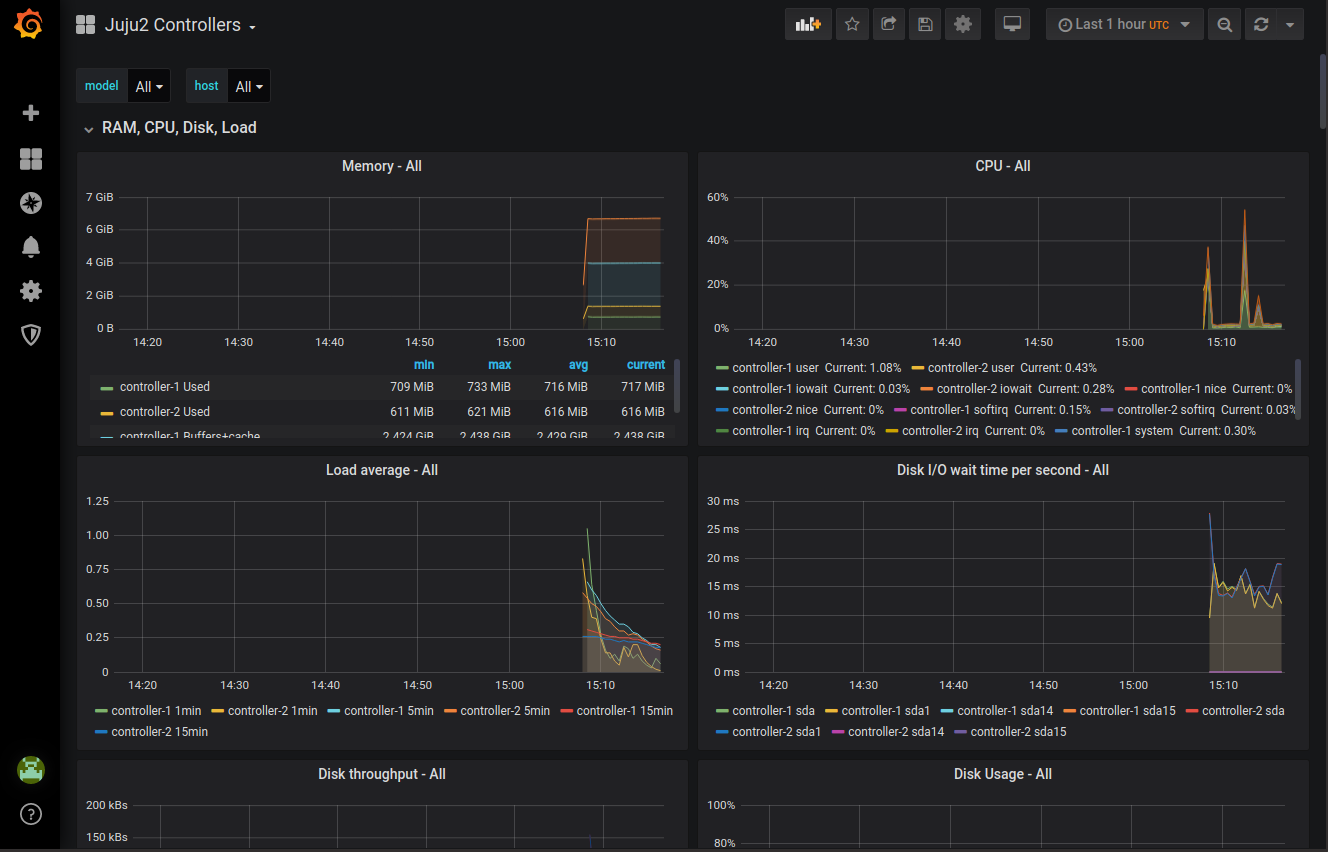
Once you’re logged in use the menu on the left to go to Dashboards->Manage->Import->upload json file. This will let us upload our dashboard.json file that’s in the controller-monitor directory we pulled down.
With that loaded you should have a pretty graph of data that you can use to kick off your controller monitoring project.
Where to go from here
Ideally we’d be able to not have to hand edit the overlay.yaml and be able to relate to the controller machines themselves. It might be interesting to have a more natural controller charm that we use instead of the ubuntu-lite charm.
We would setup alerting because what good is measuring if we don’t get a giant hint that things are heading out of whack?
What are we missing? Comment below with any issues you find following this or what other things you’d like to see in here!