
Questions from Ask Ubuntu, Server Fault and Stack Overflow since 2020-03-03T00:00:00Z tagged with Juju.
askubuntu
Failed to bootstrap model: cannot start bootstrap instance
I’ve created a mini virtual lab where have implemented on a host a virtual environment with KVM and used virt-manager to create 2 VM for Maas and Juju. Both the VM are right and that one for Juju is in ready status on Maas.
During the bootstrap of virtual node via Juju command:
> $:juju bootstrap maas-cloud maas-cloud-controller --to ulab-juju-controller --debug
the result is was that:
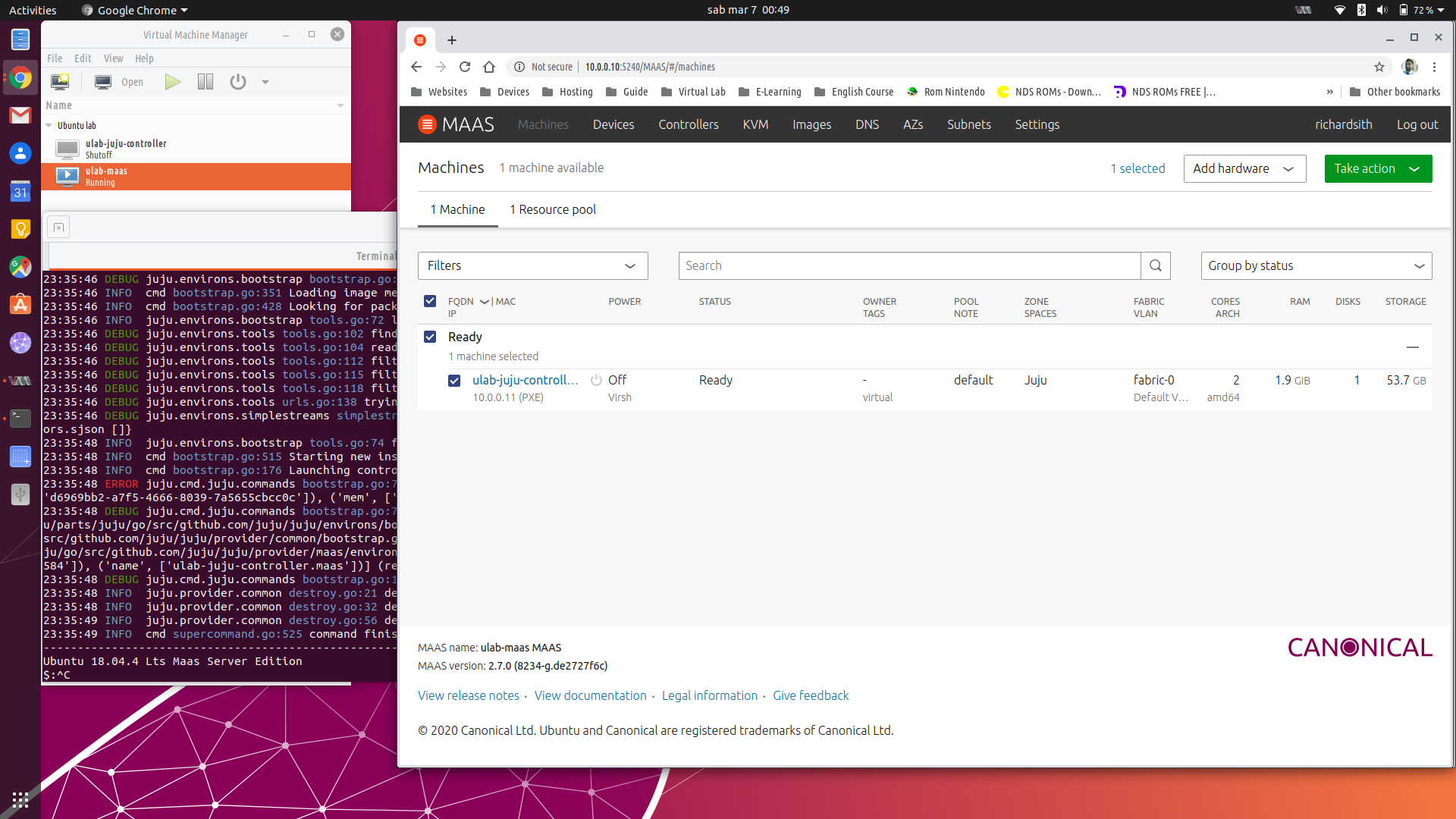
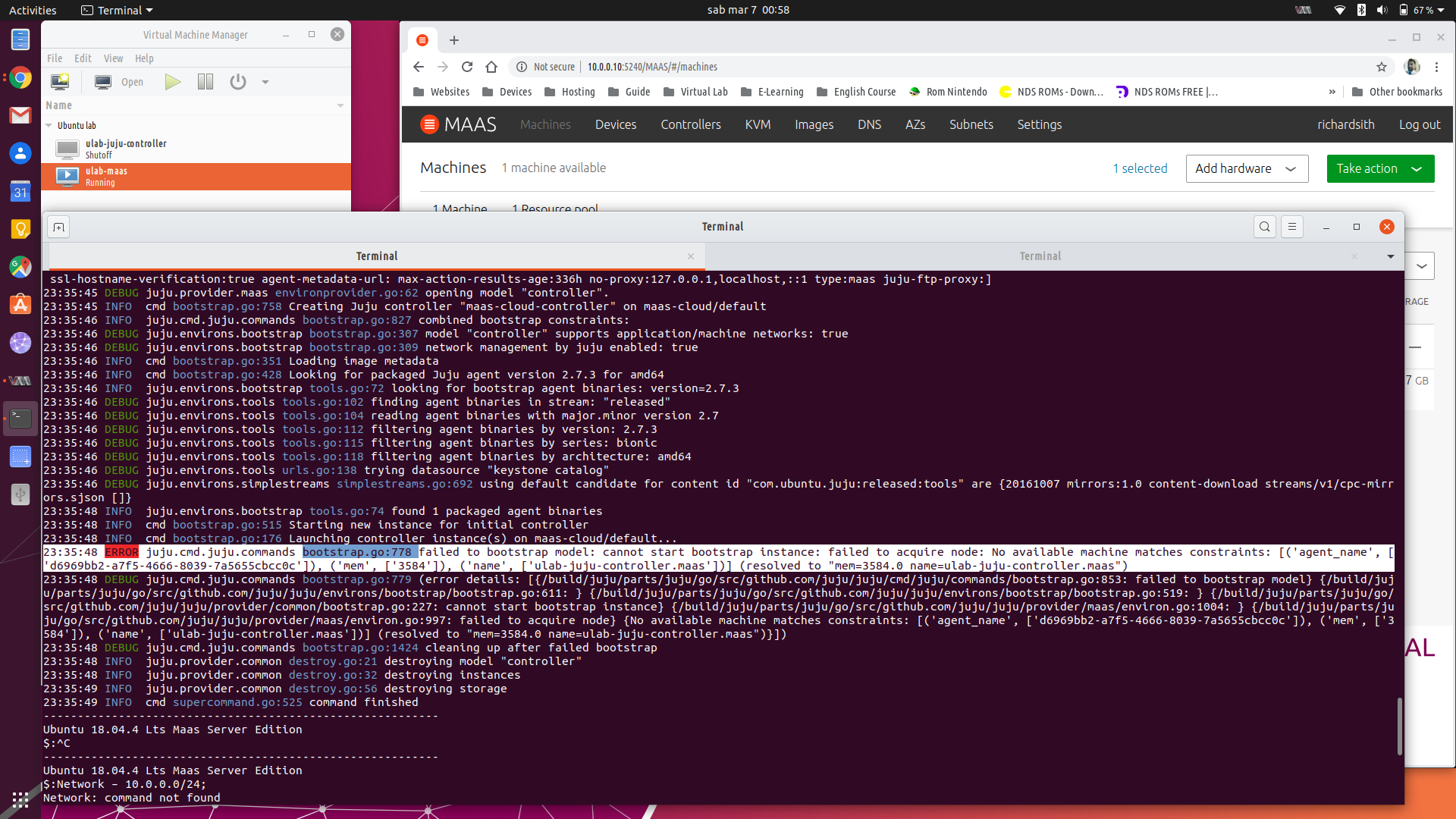
> … juju.cmd.juju.commands bootstrap.go:778 failed to bootstrap model:
> cannot start bootstrap instance: failed to acquire node: No available
> machine matches constraints: [(‘agent_name’,
> [‘d6969bb2-a7f5-4666-8039-7a5655cbcc0c’]), (‘mem’, [‘3584’]), (‘name’,
> [‘ulab-juju-controller.maas’])] (resolved to “mem=3584.0
> name=ulab-juju-controller.maas”)considered that I’ve already created a new cloud and adding a credential with:
> $: juju add-cloud and $: juju add-credential maas-cloud
I try to run this command without indicate the node
> $: juju bootstrap maas-cloud maas-controller --debug
and the result is different, the bootstrap of the node is started but another one…at this point which is the problem?
someone can help me? thanks in advance.

How to configure one Linux Bridge with two physical interfaces in MAAS?
I'm pretty new in using MAAS (and juju) for my company internal Openstack deployment; In the past I used kolla-ansible.
More details on installation and environment:
Ubuntu (server) 18.04.3 LTS (GNU/Linux 5.3.0-29-generic x86_64);
MAAS version 2.6.1We have a Dell Poweredge C6420, with 4 nodes, each of them provided with 2 Mellanox 100Gb adapters; Cause of we don't have a 100Gb capable switch to interconnect the nodes, in the past:
- First of all we have physically cross-connected the nodes
- (and then) We used Linux Bridge: Each node with a br0 and the 2 Mellanox adapters connected to it.
In this way we were able to interconnect the 4 nodes, avoiding loops by enabling STP on each br0. Everything worked fine, 4 vlans ran on that network configuration (one for Openstack internals endpoint, one for storage, one for swift, one for ceph cluster and so on).
After this (golden!) period of Kolla-ansible R&D, company decided to switch to Juju+Maas.
Now we are in trouble for replicating same configuration with MAAS (both cli and web dashboard).
What we want to do (out-of-the-box) in MAAS is:
configure one Linux Bridge, br0, and attach both network adapters of each node to it.
But Maas permit to create one br0 for one interface and this is not exactly what we want.We didn't found a way to do this. The only one way was to, use a cloud-init base64 encoded script and use MAAS cli (as documented on maas custom setup doc page). Unfortunatelly Curtin didn't work.
But, questions are:
- How is possible to replicate the configuration described above out-of-the-box in Maas?
- Even if we workaround the problem by using Maas cli and base64 encoded cloud-init script, when we'll deploy Openstack base bundle, is there a way to preserve this (handcrafted) network configuration? Or Juju deploy we'll destroy it?
Thanks in advance
stackoverflow
I pay for a large(ish) server from Hetzner, and I wanted to get more things running on it. As I have been working with Kubernetes a lot over the past year or so I looked into installing a Kubernetes cluster on a single machine.
I found a way to do this with Ubuntu and that was to use
conjure-up. This has worked well and when I am SSH'ed into the machine I am able to runkubectlcommands and see the state of the cluster.What I am not able to work out, and I am sure it is something simple that I missed, is how to make the API accessible over the public IP address and then eventually Ingress services.
I can see the internal services using
kubectl cluster-info:Kubernetes master is running at https://10.106.77.143:6443 Heapster is running at https://10.106.77.143:6443/api/v1/namespaces/kube-system/services/heapster/proxy CoreDNS is running at https://10.106.77.143:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy Metrics-server is running at https://10.106.77.143:6443/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy Grafana is running at https://10.106.77.143:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy InfluxDB is running at https://10.106.77.143:6443/api/v1/namespaces/kube-system/services/monitoring-influxdb:http/proxy(IP addresses have been changed)
Any pointers on this would be greatly appreciated.
serverfault
No questions for this period.